- Published on
Co nieco o System Designie - projektujemy komunikator (część 2)
- Authors

- Name
- Piotr Kołodziejczyk
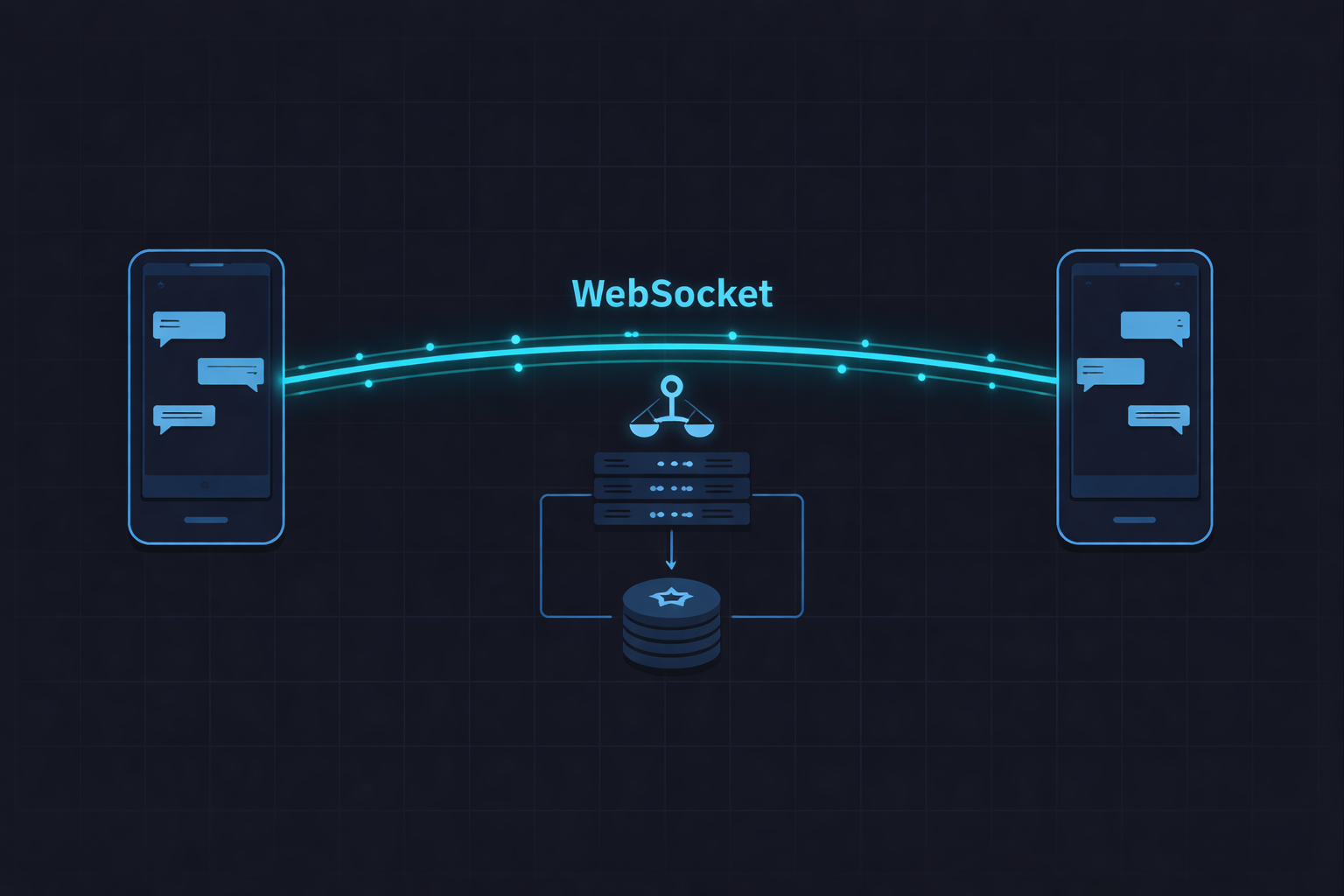
W pierwszej części ustaliliśmy wymagania, policzyliśmy skalę i wybraliśmy komponenty AWS. Teraz rozkładamy system na czynniki pierwsze - jak wiadomości faktycznie płyną od nadawcy do odbiorcy i dlaczego każda decyzja jest taka, a nie inna.
Problem fundamentalny: wiele serwerów, jedno połączenie
WebSocket to trwałe połączenie TCP między klientem a konkretnym serwerem. Jeśli mamy 20 serwerów czatu za load balancerem, Ania może być podłączona do serwera A, a Bartek do serwera D. Serwer A nie może bezpośrednio wysłać wiadomości przez serwer D - musi wiedzieć że Bartek tam jest i jakoś się z serwerem D porozumieć.
To jest centralny problem całej architektury. Redis jest jego rozwiązaniem.
Redis - rejestr połączeń
Każdy serwer czatu, gdy klient nawiązuje połączenie WebSocket, zapisuje w Redis:
SET connection:{userId} {serverIP}:{port} EX 86400
Gdy klient rozłącza się lub połączenie pada, wpis jest usuwany (albo wygasa przez TTL jako zabezpieczenie).
Struktura danych w Redis
# Mapowanie użytkownik → serwer
connection:user_123 → "10.0.1.45:8080"
connection:user_456 → "10.0.1.67:8080"
# Status online/offline (z TTL odświeżanym co 30s przez heartbeat)
presence:user_123 → "online" (TTL: 60s)
presence:user_456 → "online" (TTL: 60s)
# Typing indicator (krótkie TTL - wygasa samo)
typing:conv_789:user_123 → "1" (TTL: 5s)
Heartbeat: klient wysyła ping co 30 sekund, serwer odświeża TTL klucza presence. Jeśli klient padnie bez graceful disconnect, TTL wygaśnie i użytkownik automatycznie przejdzie w offline po ~60 sekundach.
Przepływ wiadomości P2P - happy path (obaj online)
Ania (klient) ALB Serwer A Redis Serwer D Bartek (klient)
│ │ │ │ │ │
│── msg: "Cześć!" ──────▶│ │ │ │ │
│ │── WebSocket ─▶│ │ │ │
│ │ │ │ │ │
│ │ │─ GET connection:bartek_id ──▶│ │
│ │ │ │◀── "10.0.1.67" ──│ │
│ │ │ │ │ │
│ │ │── HTTP /internal/deliver ──▶│ │
│ │ │ │ │──WebSocket──▶│
│ │ │ │ │ │
│ │ │─ WRITE do DynamoDB ──────────────── │
│ │ │ │ │ │
│◀── ACK: "delivered" ───│ │ │ │ │
Kroki szczegółowo:
1. Ania wysyła wiadomość
Klient wysyła przez WebSocket JSON:
{
"type": "message",
"to": "bartek_id",
"content": "Cześć!",
"client_msg_id": "uuid-generated-client-side",
"timestamp": 1713265200000
}
client_msg_id generowany po stronie klienta - chroni przed duplikatami przy retransmisjach.
2. Serwer A przetwarza wiadomość
- Waliduje token autoryzacji Ani
- Generuje
server_msg_id(np. ULID - sortowalne UUID) - Sprawdza Redis:
GET connection:bartek_id - Zapisuje wiadomość do DynamoDB (patrz schemat niżej)
- Zwraca Ani ACK z
server_msg_id
3. Dostarczenie do serwera D
Serwer A wywołuje wewnętrzny HTTP endpoint serwera D (adresy IP są widoczne w ramach VPC):
POST http://10.0.1.67:8080/internal/deliver
{
"msg_id": "01J2K...",
"to": "bartek_id",
"from": "ania_id",
"content": "Cześć!",
"timestamp": 1713265200000
}
Serwer D szuka połączenia WebSocket Bartka i wysyła wiadomość.
4. Potwierdzenie odczytania
Bartek widzi wiadomość → klient automatycznie wysyła read receipt:
{ "type": "read_receipt", "msg_id": "01J2K...", "conversation_id": "conv_789" }
Serwer aktualizuje status w DynamoDB i informuje Anię (serwer D → serwer A → Ania).
Przepływ wiadomości - Bartek offline
Gdy Redis nie ma wpisu connection:bartek_id:
Serwer A:
1. Zapisz wiadomość do DynamoDB (status: "sent")
2. Wyślij ACK do Ani (status: ✓)
3. Push: SQS → Lambda → SNS → FCM/APNs
┌─────────────────────────────────────────┐
Serwer A ──────────▶│ SQS: notification-queue │
└──────────────┬──────────────────────────┘
│
┌──────────────▼──────────────────────────┐
│ Lambda: notification-dispatcher │
└──────────────┬──────────────────────────┘
│
┌──────────────▼──────────────────────────┐
│ SNS Topic: push-notifications │
├──────────────────────────────────────────┤
│ FCM (Android) │ APNs (iOS) │
└─────────────────────────────────────────┘
Gdy Bartek wraca online:
- Nawiązuje połączenie WebSocket
- Serwer czatu rejestruje go w Redis
- Klient od razu odpytuje DynamoDB o nieprzeczytane wiadomości (pull przy starcie)
- Status wiadomości zmienia się z "sent" → "delivered" → "read"
Schemat DynamoDB
DynamoDB wymaga świadomego projektowania. Źle dobrane klucze = drogo i wolno.
Tabela: messages
| Klucz | Typ | Opis |
|---|---|---|
PK (partition key) | String | CONV#{conversation_id} |
SK (sort key) | String | MSG#{ulid} - ULID gwarantuje sortowanie wg czasu |
sender_id | String | ID nadawcy |
content | String | Treść (lub null dla mediów) |
media_key | String | Klucz S3 (jeśli wiadomość zawiera media) |
status | String | sent / delivered / read |
created_at | Number | Unix timestamp (ms) |
expires_at | Number | TTL dla DynamoDB - auto-delete po N latach |
Zapytanie o historię konwersacji (ostatnie 50 wiadomości):
Query:
KeyConditionExpression: PK = "CONV#conv_789" AND SK > "MSG#01J1..."
ScanIndexForward: false (malejąco - od najnowszych)
Limit: 50
Jeden Query, korzystający z indeksu partycji. Żadnego Scan.
Tabela: conversations
PK: USER#{user_id}
SK: CONV#{conversation_id}
Atrybuty:
- other_user_id
- last_message_preview
- last_message_at
- unread_count
Lista rozmów użytkownika to pojedyncze Query po PK = USER#{user_id}, sortowane po last_message_at przez GSI.
WebSocket i Load Balancer - szczegóły
ALB obsługuje WebSocket natywnie - connection upgrade z HTTP do WS jest transparentny. Kluczowa konfiguracja:
Sticky sessions - NIE używamy. Sticky sessions na ALB oznaczają, że klient zawsze trafia do tego samego serwera - co łamie horizontal scaling przy awarii. Zamiast tego rejestrujemy serwer w Redis przy każdym połączeniu. ALB może kierować do dowolnego zdrowego serwera.
Idle timeout - ALB domyślnie zamyka połączenia po 60 sekundach braku aktywności. Klient wysyła heartbeat ping co 30 sekund - zapobiega zamknięciu.
Health checks - ALB sprawdza /health na każdym serwerze co 10 sekund. Serwer z problemami jest wyłączany z rotacji w ciągu ~30 sekund. Klienci tracą połączenie WebSocket i łączą się automatycznie (retry z exponential backoff po stronie klienta).
Reconnect flow klienta
// Pseudokod logiki reconnect
const connect = () => {
const ws = new WebSocket(WS_URL)
ws.onclose = () => {
const delay = Math.min(1000 * 2 ** attempt, 30000) // max 30s
setTimeout(connect, delay + Math.random() * 1000) // jitter
attempt++
}
ws.onopen = () => {
attempt = 0
syncMissedMessages() // pull z DynamoDB po reconnect
}
}
Jitter (losowe opóźnienie) jest krytyczny - bez niego tysiące klientów próbuje połączyć się dokładnie w tym samym momencie po awarii serwera (thundering herd problem).
Upload i pobieranie zdjęć
Upload - presigned S3 URL
Klient nie wysyła zdjęcia przez serwer czatu - to byłoby wąskie gardło. Przepływ:
1. Klient → serwer czatu: "chcę wysłać zdjęcie do conv_789"
2. Serwer → S3: generuj presigned PUT URL
- Klucz: media/{conv_id}/{ulid}.jpg
- TTL: 5 minut
- Max rozmiar: 25 MB
- Allowed content types: image/jpeg, image/png, image/webp
3. Serwer → klient: { "upload_url": "https://s3.amazonaws.com/...", "media_key": "media/..." }
4. Klient → S3 bezpośrednio: PUT zdjęcie (przez presigned URL)
- S3 weryfikuje sygnaturę - żadnego dodatkowego autoryzacji
- Progress bar działa normalnie (bezpośrednie połączenie)
5. Klient → serwer czatu: "upload gotowy" + media_key
6. Serwer:
a. Wrzuca do SQS zadanie: "skompresuj i stwórz miniatury"
b. Zapisuje wiadomość do DynamoDB z media_key (status: "sent")
c. Dostarcza do odbiorcy jak zwykłą wiadomość
Lambda do przetwarzania mediów
S3 Event → SQS → Lambda (image-processor):
1. Pobierz oryginał z S3
2. Stwórz miniaturę 320×320 px
3. Zapisz z kluczem: media/{conv_id}/{ulid}_thumb.jpg
4. Zaktualizuj DynamoDB: dodaj thumbnail_key
Klient najpierw pokazuje miniaturę (szybkie ładowanie), full-res tylko na żądanie (tap).
Pobieranie przez CloudFront
Klient nigdy nie sięga bezpośrednio do S3. Używa CloudFront URL:
https://media.naszkomunikator.pl/media/{conv_id}/{ulid}.jpg
│
▼
CloudFront CDN
(edge location ~50ms)
│
(cache miss - tylko raz)
▼
Amazon S3
(origin, ~200ms)
CloudFront cache'uje zdjęcie na edge po pierwszym pobraniu. Każde następne odwołanie - serwowane z cache, bliskie latencji sieci.
Cache-Control: zdjęcia są immutable (klucz zawiera ULID unikalny dla każdego uploadu) - ustawiamy Cache-Control: max-age=31536000, immutable. CloudFront trzyma je rok. Żadnych problemów z inwalidacją.
Rate limiting i ochrona
Redis idealnie nadaje się do rate limitingu algorytmem sliding window:
Klucz: ratelimit:{user_id}:{window_start}
Wartość: liczba wiadomości w oknie
TTL: czas okna (np. 60s)
Logika (Lua script - atomowy w Redis):
current = INCR ratelimit:{user_id}:{current_minute}
EXPIRE ratelimit:{user_id}:{current_minute} 60
if current > 100:
return "rate_limited"
Przy 100 wiadomościach na minutę jako limit: normalny użytkownik nigdy go nie osiągnie (~0.67/s), bot zostanie zablokowany.
Pełny diagram komunikacji
┌─────────────────────────────────────────────────────┐
│ AWS VPC │
│ │
Klienci │ ┌──────┐ ┌──────────────────────────────────┐ │
mobile/web ───────────▶│ │ ALB │───▶│ Chat Servers (ECS Fargate) │ │
WebSocket │ │(WSS) │ │ │ │
│ └──────┘ │ ┌────────┐ ┌────────────────┐ │ │
│ │ │Serwer A│ │ Serwer B │ │ │
│ │ └───┬────┘ └───────┬────────┘ │ │
│ └──────┼───────────────┼──────────┘ │
│ │ │ │
│ ┌──────────┼───────────────┼────────┐ │
│ │ ▼ ▼ │ │
│ │ ┌─────────────────────────┐ │ │
│ │ │ ElastiCache (Redis) │ │ │
│ │ │ - connection registry │ │ │
│ │ │ - presence/TTL │ │ │
│ │ │ - rate limiting │ │ │
│ │ │ - typing indicators │ │ │
│ │ └─────────────────────────┘ │ │
│ │ │ │
│ │ ┌─────────────────────────┐ │ │
│ │ │ DynamoDB │ │ │
│ │ │ - messages table │ │ │
│ │ │ - conversations table │ │ │
│ │ └─────────────────────────┘ │ │
│ │ │ │
│ │ ┌──────┐ ┌───────┐ │ │
│ │ │ SQS │─▶│Lambda │ │ │
│ │ └──────┘ └───┬───┘ │ │
│ └──────────────────┼────────────────┘ │
│ │ │
│ ┌──────────────┤ │
│ ▼ ▼ │
│ ┌────────┐ ┌──────────┐ │
│ │ SNS │ │ S3 │◀── presigned │
│ └───┬────┘ │ (media) │ PUT (klient) │
│ │ └────┬─────┘ │
└─────────────┼─────────────┼──────────────────────-┘
│ │
FCM/APNs│ CloudFront
(push) │ (CDN)──▶ klienci
Czego nie ma w tym artykule (celowo)
Kilka tematów zasługuje na osobny wpis:
- End-to-end encryption - Signal Protocol, przechowywanie kluczy, double ratchet
- Grupy - fan-out do N użytkowników, grup 1000+ osób wymaga zupełnie innego podejścia
- Multi-device - ten sam klient na telefonie i laptopie, synchronizacja stanu
- Archiwizacja - tiered storage, przenoszenie starych wiadomości do S3 Glacier
System który opisaliśmy obsługuje realny ruch przy rozsądnych kosztach. Kluczowe decyzje:
- Redis jako rejestr połączeń eliminuje problem "różne serwery WebSocket"
- DynamoDB z ULID jako SK daje sortowanie chronologiczne za darmo
- Presigned S3 URL eliminuje serwery czatu jako wąskie gardło przy mediach
- Exponential backoff z jitterem chroni przed thundering herd
- CloudFront z
immutablecache minimalizuje koszty transferu S3